Guideline for Building a Practical and Effective RAG (Retrieval-Augmented Generation) Application

Preface
This article is based on my hands-on experience in building practical and effective Retrieval-Augmented Generation (RAG) applications. Rather than just walking through the setup, I’ll focus on what truly matters — making RAG useful in real-world scenarios.
If you have insights, alternative approaches, or suggestions, I’d love to hear them!
I assume you’re already familiar with the fundamentals and benefits of RAG. If not, I recommend checking out some foundational resources before diving in. While this guide is based on Azure AI Search, the principles apply to other technologies as well.
To keep things practical and easy to follow, each step will be structured into two parts:
- Concept & Approach — What needs to be done and why it matters
- Real-World Scenario — A concrete example illustrating the process in action
By following along, you won’t just learn how to build a RAG application — you’ll learn how to make it truly useful in production. Let’s get started! 🚀
Step1: Clarify the Requirements
Concept & Approach
Before jumping into implementation, it’s crucial to define what your RAG application should accomplish. A well-defined goal ensures the solution is practical and delivers real value.
For example, if employees struggle to find internal documents, a RAG-powered system can help — but what exactly should it do? Should it only retrieve relevant files, or should it also generate concise AI summaries? Should users access the original files, or should they primarily interact with extracted content and AI-generated summaries?
Clarifying these requirements upfront prevents wasted effort and ensures the solution aligns with actual needs.
Real-World Scenario
For this guide, we’ll assume that both the user queries and documents are in the same language. Our goal is to enable users to:
- Receive AI-generated summaries derived from the most relevant documents.
- View detailed information about the relevant documents, including their file names and locations.
- Click on hyperlinks to directly access the relevant documents.
Example Query:
How do I apply for reimbursement for an overseas business trip?
Example AI-Generated Summary:
Submit an Expense Report with receipts, an Approval Form signed by your manager, and a Travel Itinerary. Ensure expenses comply with company policy. Attach invoices and proof of payment. Submit through the expense system or finance department. Keep copies for records and audits.
Related Files (ranked by relevance):
- Expense_Report_Template.xlsx
- Business_Trip_Approval_Form.pdf
- Travel_Itinerary_Sample.docx
By setting clear expectations, we ensure our RAG application delivers real business value, rather than just being a fancy search tool.
Now, let’s dive into making this work! Below is an image to help you visualize the application.

Step2: Assess the input data
Concept & Approach
Before adding document content to a search service (e.g., Azure AI Search), it’s essential to understand and assess the input data. This helps in designing an efficient ingestion process and avoiding unexpected challenges. Key factors to consider include:
File Types & Sizes
- What types of documents will the system process? PDFs, Word files, Excel spreadsheets?
- What are the average and maximum file sizes? This helps estimate processing time and storage needs.
Chunking & Overlap Strategy
- Rather than diving into specific chunking & overlap strategies here, I encourage you to research best practices that fit your data and use case.
Data Extraction Requirements
- Do files contain images with embedded text? If so, should OCR (Optical Character Recognition) be used? (e.g., Azure Document Intelligence)
- Should images themselves be analyzed using vision models?
Extraction Tools
- Should we use open-source libraries?
- Or opt for cloud-based solutions like Azure Document Intelligence.
Preprocessing Needs
- Are there unsupported formats requiring conversion before ingestion?
Real-World Scenario
For this guide, let’s assume our input dataset consists of:
File Types & Sizes
You can estimate the time required to process all file contents into Azure AI Search by considering the number of files, as well as the TPM/RPM and token limitations of the embedding model. This will help determine the application’s release date.
Chunking & Overlap Strategy
For Excel, our chunking strategy is based on tokens for each sheet. Depending on the use case, you can also treat each row as a separate chunk.
Data Extraction Requirements
- Extract text from images using OCR
Extraction Tools
- Since costs are acceptable, we’ll use Azure Document Intelligence
Preprocessing Needs
- No special file format conversions required
By thoroughly assessing input data before implementation, we can ensure a smooth document processing for our RAG application.
Now that we have a clear understanding of our data, let’s move on to the next step!
Step3: Define Accuracy Metrics
Concept & Approach
After defining requirements and preparing data, it’s crucial to establish how to evaluate the accuracy of your RAG system. Without clear metrics, you won’t know if the system is performing well or needs improvements.
Key Considerations
- What defines a “correct” result? For example:
・ For relevant documents, should the top 3 or top 10 search results contain the right document?
・ For summarization, how do we judge its accuracy? - Granularity of Evaluation — Should accuracy be measured at the document level or at a more detailed level (e.g., page, section, or spreadsheet sheet)?
- Acceptable Accuracy Rate — What percentage of correct results is considered good enough for production use?
Real-World Scenario
To evaluate our RAG system, we define accuracy criteria as follows:
- Relevant Documents — A search result is considered correct if the top 10 retrieved results contain the expected document and location.
- Summarization — A summary is considered correct if it covers the key expected points.
- Acceptable Accuracy Rate — We initially set the target accuracy at:
・60% for relevant document retrieval
・50% for summarization
To systematically evaluate performance, prepare an Excel sheet like the one shown below. This structured approach helps assess search and summarization accuracy:
- User Query — Sample questions users might ask.
- Retrieved File Name — The filename of the retrieved document.
- Retrieved Position — The location of the retrieved content (e.g., page number for PDFs, sheet name for Excel files).
- Retrieved Content — The specific content retrieved from the document.
- Expected File Name — The correct file that should be retrieved.
- Expected Position — The correct location of the expected content.
- Summarization Result — The AI-generated summary.
- Expected Summarization Result — Since AI-generated summaries may vary, define key points that should be included to determine correctness.
- Is Retrieved Search Result Correct? — Yes/No.
- Is Summarization Correct? — Yes/No.
- Summarization Result Evaluation — If incorrect, provide an explanation to help analyze the issue and identify potential improvements.
By defining clear accuracy metrics, you ensure your RAG system is measurable, reliable, and continuously improvable.
Step4: Design the Application Architecture and Azure AI Search Schema
Concept & Approach
Architecture

A typical RAG application consists of:
- Search Service — Such as Azure AI Search.
- AI Service — Such as Azure OpenAI.
- OCR Service — Such as Azure Document Intelligence.
- Frontend Server — Accepts user queries and displays search results & summaries.
- Backend Server — Processes queries, interacts with Azure AI Search & GPT and Embedding models.
- Batch Processing Server — Extracts document content, and interacts with Embedding model, and adding data to Azure AI Search. Depends on needs, documents be imported manually, periodically, or automatically as soon as they’re updated? If updates are frequent, an automated ingestion pipeline is essential.
- Storage — The place where documents be stored (e.g., SharePoint, local servers, or other cloud storage). Sometime it is also related to how you are going to maintain the documents.
- Database — In the initial stage, you might not need this. However, depending on the requirements, you can add a database to store the extracted content from the OCR model, reducing costs when uploading the same document to another Azure AI Search index. You can also use the database to save users’ search histories.
Designing Azure AI Search Index Schema
Think of Azure AI Search as similar to a relational database, which can help you imagine its functionality. Its index just like table. Its fields just like columns ! When designing the schema, you first need to know what properties we should set for each field:
- Retrievable: Determines which fields are returned in search results. Follow the principle of least privilege — retrieve only necessary fields in production but enable all fields during development for debugging.
- Searchable: Defines which fields are indexed for text search. Set only relevant fields as searchable.
- Filterable: Enables filtering on certain fields. Useful for optimizing search results.
- Depending on your needs, you may require Sortable and Facetable properties.
Important Considerations
- Search order is consistent for the same query unless new documents are added.
- Filterable and searchable settings cannot be changed after index creation — careful planning is required.
- Other search approaches, such as hybrid search, can also be explored for optimization.
Real-World Scenario
Architecture
- For Azure OpenAI, we need both a GPT model and an embedding model. The embedding model is used during data ingestion to generate vector representations for storage in Azure AI Search. It is also used to convert queries into vectors for performing vector searches.
- Documents are stored in SharePoint and maintainer will update the files to the latest. It also means that there are not the same file for different version.
- An automated import process runs daily to keep content up to date.
Azure AI Search Index Schema
We assume Azure AI Search index’ fields contains:
- file_name:
・name of the file
・Retrievable-true, Searchable-false, Filterable-false - chunk_content
・real content in the chunk
・Retrievable-true, Searchable-true, Filterable-false - chunk_content_position
・location in the file like page or sheet_name
・Retrievable-true, Searchable-false, Filterable-false - chunk_content_vector
・vectorized result for chunk content
・Retrievable-true, Searchable-true, Filterable-false - file_link
・The original file link for the end-use to browse
・Retrievable-true, Searchable-false, Filterable-false - document_category
・Customized for filter, we asuume the content will be some category of documents. It’s one of the optimized strategy when accuracy is not enough.
・Retrievable-true, Searchable-false, Filterable-true
Below is an illustration that differs from the fields I mentioned earlier, but it will help you easily understand the properties of an Azure AI Search index field. The image is referenced from the Microsoft Dev Blogs.
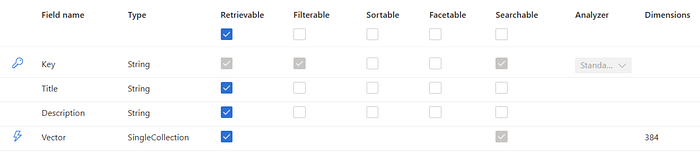
Step5: Implement the Application
This step is not covered in detail, as many online tutorials provide code examples for implementing RAG applications.
Step6: Import Data into Azure AI Search
Concept & Approach
Start by running the batch processing server to handle data ingestion. Consider implementing error handling to manage document upload failures. If a document fails to upload, determine a strategy to recover from partial uploads and ensure data consistency.
Real-World Scenario
To keep things simple, if a document fails during the upload process and only part of it is ingested, we should delete all related data and reprocess the document from scratch.
By carefully designing the strategy for updating the data in the Azure AI Search index, we ensure our RAG system stays up to date, remains efficient, and meets user needs.
Step7: Execution
Concept & Approach
Refer back to the accuracy metrics defined in Step 3 and use a predefined Excel sheet to execute the evaluation. You can perform this manually or automate it with a script.
Real-World Scenario
If executed manually, the process would follow these steps:
- Enter sample queries into the RAG application.
- Retrieve both the search results and the summarization output from the RAG application.
- Record these results in the Excel sheet.
- Compare them with the expected answers.
- Calculate accuracy rates based on the recorded data.
Step8: Analyze Results and Optimize
Concept & Approach
Once we determine the accuracy rates, we can decide whether further optimization is needed or if we can expand access to more users to collect feedback. At the same time, we should analyze incorrect results to identify possible causes and optimize the system accordingly.
Real-World Scenario
Below are some common issues that may lead to incorrect responses:
Search Result Issues
- Too many irrelevant documents: If the search service contains excessive noise, it may dilute relevant results.
- Ambiguous queries: Users may need guidelines on how to phrase better questions.
- Chunk size & overlap tuning: Adjusting these parameters can improve retrieval accuracy but requires re-ingesting data, which can be costly.
Summarization Issues
- Prompt engineering — Refining the prompts sent to the generative AI model can enhance summarization quality. Using structured prompts with a fixed template often yields better results.
- Excessive search results passed to Azure OpenAI: Passing too many search results to Azure OpenAI can sometimes degrade the answer quality. If search result accuracy is sufficient, we can fine-tune the number of top results passed to Azure OpenAI to improve summarization output.
Conclusion
Building a useful RAG application extends beyond technical implementation. Key considerations include:
- Document maintenance: Ensure the dataset remains relevant and up to date. The responsible team should update source documents regularly.
- Long-term sustainability: Implement a robust feedback loop and continuous refinement process.
By focusing on usability and iterative improvements, your RAG application can remain effective and valuable over time.
